
Um recurso interessante do sistema de arquivos que descobri há alguns anos são os arquivos esparsos. Resumindo, muitos sistemas de arquivos permitem criar um arquivo lógico com blocos “vazios” (totalmente zerados) que não recebem backup físico até serem gravados. Copiando parcialmente do ArchWiki, o comportamento é assim:
O arquivo começa com 0 bytes físicos no disco, apesar de ter logicamente 512 MB. Então, depois de escrever alguns bytes diferentes de zero em um deslocamento de 16 MB, ele aloca fisicamente um único bloco (4 KB). O sistema de arquivos mantém metadados sobre quais blocos do arquivo estão fisicamente representados no disco e quais não estão. Para leitores normais do arquivo, é transparente – a dispersão é gerenciada completamente pelo sistema de arquivos.
Na Amplitude, encontramos um caso de uso interessante para arquivos esparsos. Todos os dados são armazenados de forma durável em armazenamento frio (Amazon S3) em um formato de dados colunar usado para consultas analíticas. Mas é ineficiente e caro buscá-los sempre no S3, de modo que os dados são armazenados em cache em SSDs NVMe locais (por exemplo, da classe de instância r7gd). No entanto, esses SSDs locais são dez vezes mais caros que o armazenamento frio, portanto, você precisa de uma boa estratégia para decidir como e o que armazenar em cache. Para entender por que arquivos esparsos são uma boa opção para isso, vamos revisitar brevemente os formatos de dados colunares.
Uma das observações sobre consultas analíticas que torna os formatos de dados colunares tão eficazes é o fato de que normalmente apenas um pequeno subconjunto de colunas (5 a 10 entre potencialmente milhares) é usado em qualquer consulta específica (e, até certo ponto, até mesmo em muitas consultas). O armazenamento dos dados em colunas significa que cada uma dessas colunas é um intervalo contíguo dentro do arquivo, tornando a leitura muito mais rápida. Os intervalos contíguos também são importantes no contexto do nosso cache local – não estamos tentando selecionar pequenos pedaços espalhados pelo arquivo.
Deixando os arquivos esparsos de lado por um momento, originalmente tínhamos duas abordagens diferentes para fazer esse armazenamento em cache:
- A estratégia mais ingênua é armazenar em cache arquivos inteiros do S3. Isso é simples e requer um mínimo de metadados para gerenciar, mas tem a desvantagem óbvia de desperdiçar muito espaço em disco nos SSDs armazenando colunas que raramente ou nunca são usadas.
- Outra opção é armazenar em cache colunas diferentes como arquivos individuais no disco. Isso resolve um pouco o problema de desperdício de espaço em disco, mas agora aumenta o número de arquivos, o que requer uma quantidade substancial de metadados do sistema de arquivos. Ele também enfrenta colunas pequenas, que são arredondadas para o tamanho do bloco do sistema de arquivos. Com centenas de milhares de clientes de tamanhos variados, é inevitável que a grande maioria dos arquivos/colunas sejam pequenos.
Neste ponto, está bem claro como os arquivos esparsos oferecem uma opção entre esses dois. Imaginamos que estamos armazenando arquivos inteiros em cache, exceto que os arquivos são esparsos, onde apenas as colunas usadas (mais especificamente, os blocos lógicos que contêm essas colunas) estão fisicamente presentes. Isso é mais simples para o consumidor ler e utilizar melhor o disco – menos metadados do sistema de arquivos e pequenas colunas são consolidadas em blocos do sistema de arquivos (como bônus, isso também reduz GETs do S3). Semelhante à última abordagem acima, os consumidores devem declarar as colunas de que precisam no cache antes de lê-las.
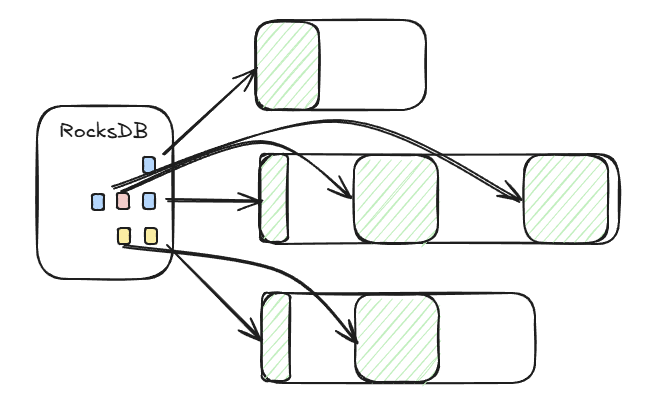
| Gerenciando metadados de blocos de arquivos esparsos no RocksDB. |
Este sistema exige que gerenciemos metadados em quais colunas são armazenadas em cache, para os quais usamos uma instância local do RocksDB. Mais especificamente, rastreamos metadados em blocos lógicos desses arquivos esparsos: quais estão presentes localmente e quando foram lidos pela última vez. Usando isso, aproximamos uma política LRU para invalidar dados quando o disco fica cheio. Como um detalhe importante de implementação, os blocos lógicos têm tamanho variável com alguns blocos menores no cabeçalho (ainda maiores que os blocos do sistema de arquivos) e depois blocos maiores no resto, o que aproveita o fato do formato do arquivo possuir um cabeçalho de metadados (semelhante ao Parquet) que sempre precisa ser lido para saber como as colunas estão dispostas.
Esse cache LRU de arquivo esparso melhorou muitos aspectos do sistema de consulta simultaneamente: menos GETs S3, menos metadados do sistema de arquivos, menos sobrecarga de bloco do sistema de arquivos e menos IOPS para gerenciar o cache. É raro que um recurso de nível tão baixo quanto o sistema de arquivos tenha um impacto tão proeminente no design do sistema, então, quando isso acontece, é muito legal.
Fonte: theverge





