
À medida que os agentes de codificação se tornaram mais capazes, passamos a gastar mais tempo na revisão. Para resolver isso, construímos o Bugbot, um agente de revisão de código que analisa solicitações pull em busca de bugs lógicos, problemas de desempenho e vulnerabilidades de segurança antes que cheguem à produção. No verão passado, estava funcionando tão bem que decidimos liberá-lo para os usuários.
O processo de construção do Bugbot começou com avaliações qualitativas e gradualmente evoluiu para uma abordagem mais sistemática, usando uma métrica personalizada baseada em IA para aumentar a qualidade.
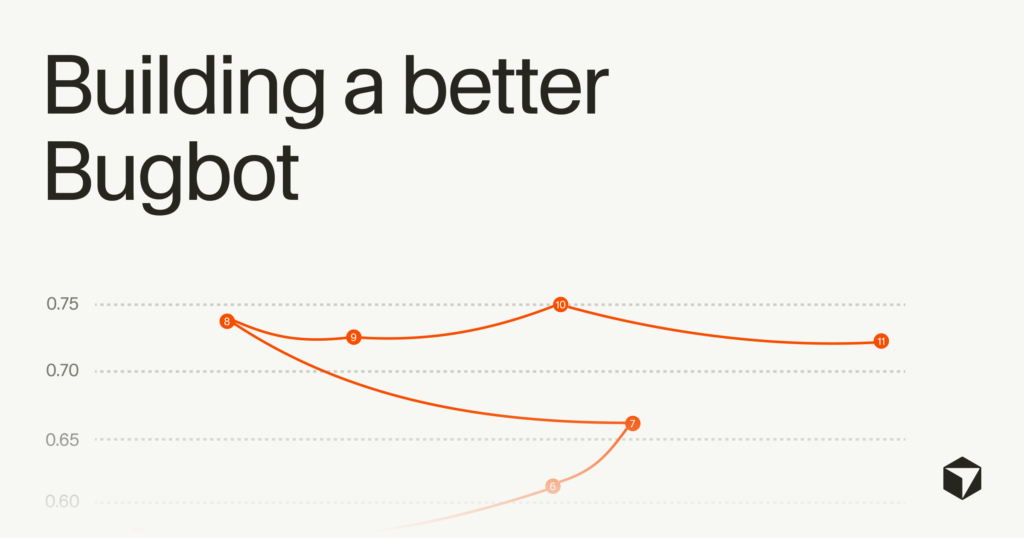
Desde o lançamento, realizamos 40 experimentos importantes que aumentaram a taxa de resolução do Bugbot de 52% para mais de 70%, ao mesmo tempo em que aumentaram o número médio de bugs sinalizados por execução de 0,4 para 0,7. Isso significa que o número de bugs resolvidos por PR mais que dobrou, de aproximadamente 0,2 para cerca de 0,5.
Começos humildes
Quando tentamos construir um agente de revisão de código pela primeira vez, os modelos não eram capazes o suficiente para que as revisões fossem úteis. Mas à medida que os modelos básicos foram melhorando, percebemos que tínhamos diversas maneiras de aumentar a qualidade dos relatórios de bugs.
Experimentamos diferentes configurações de modelos, pipelines, filtros e estratégias inteligentes de gerenciamento de contexto, consultando engenheiros internamente ao longo do caminho. Se parecesse que uma configuração tinha menos falsos positivos, nós a adotamos.
Uma das melhorias de qualidade mais eficazes que encontramos no início foi executar várias passagens de localização de bugs em paralelo e combinar seus resultados com a votação por maioria. Cada passagem recebeu uma ordenação diferente do diff, o que empurrou o modelo para diferentes linhas de raciocínio. Quando várias passagens sinalizavam o mesmo problema de forma independente, tratamos isso como um sinal mais forte de que o bug era real.
Após semanas de iterações qualitativas internas, chegamos a uma versão do Bugbot que superou outras ferramentas de revisão de código no mercado e nos deu confiança para lançar. Ele usou este fluxo:
- Execute oito passagens paralelas com ordem de comparação aleatória
- Combine bugs semelhantes em um balde
- Votação majoritária para filtrar bugs encontrados durante apenas uma passagem
- Mesclar cada intervalo em uma única descrição clara
- Filtre categorias indesejadas (como avisos do compilador ou erros de documentação)
- Execute os resultados por meio de um modelo validador para capturar falsos positivos
- Desduplicar bugs postados em execuções anteriores
Do protótipo à produção
Para tornar o Bugbot utilizável na prática, tivemos que investir em um conjunto de sistemas fundamentais juntamente com a lógica central de revisão. Isso incluiu tornar o acesso ao repositório rápido e confiável, reconstruindo nossa integração Git em Rust e minimizando a quantidade de dados que buscamos, bem como adicionando monitoramento de limite de taxa, lote de solicitações e infraestrutura baseada em proxy para operar dentro das restrições do GitHub.
À medida que a adoção crescia, as equipes também precisavam de uma maneira de codificar invariantes específicos da base de código, como migrações inseguras ou uso incorreto de APIs internas. Em resposta, adicionamos regras do Bugbot para dar suporte a essas verificações sem codificá-las no sistema.
Juntas, essas peças tornaram o Bugbot prático de executar e adaptável a bases de código reais. Mas eles não nos disseram se a qualidade estava realmente melhorando. Sem uma métrica para medir o progresso, não poderíamos avaliar quantitativamente o desempenho do Bugbot em estado selvagem, e isso estabeleceu um limite para o quão longe poderíamos ir.
Medindo o que importa
Para resolver esse problema, desenvolvemos uma métrica chamada taxa de resolução. Ele usa IA para determinar, no momento da fusão do PR, quais bugs foram realmente resolvidos pelo autor no código final. Ao desenvolver essa métrica, verificamos todos os exemplos internamente com o autor do PR e descobrimos que o LLM classificou corretamente quase todos eles como resolvidos ou não.
As equipes costumam nos perguntar como avaliar o impacto que o Bugbot está causando para elas, por isso colocamos essa métrica em destaque no painel. Para as equipes que avaliam a eficácia, é um sinal muito mais claro do que feedback anedótico ou reações aos comentários. A taxa de resolução responde diretamente se o Bugbot está encontrando problemas reais que os engenheiros resolvem.
Escalada
A definição da taxa de resolução mudou a forma como construímos o Bugbot. Pela primeira vez, poderíamos subir colinas com base em sinais reais, em vez de apenas sentir. Começamos a avaliar as alterações on-line usando taxas de resolução reais e off-line usando o BugBench, um benchmark com curadoria de diferenças de código reais com bugs anotados por humanos.
Executamos dezenas de experimentos em modelos, prompts, contagens de iterações, validadores, gerenciamento de contexto, filtragem de categorias e designs de agentes. Muitas mudanças, surpreendentemente, regrediram nossas métricas. Descobriu-se que muitos dos nossos julgamentos iniciais das primeiras análises qualitativas estavam corretos.
Arquitetura agente
Vimos os maiores ganhos quando, neste outono, mudamos o Bugbot para um design totalmente agente. O agente poderia raciocinar sobre a diferença, chamar ferramentas e decidir onde ir mais fundo em vez de seguir uma sequência fixa de passagens.
O ciclo de agência nos forçou a repensar a solicitação. Nas versões anteriores do Bugbot, precisávamos restringir os modelos para minimizar falsos positivos. Mas com a abordagem agencial encontrámos o problema oposto: foi demasiado cauteloso. Mudamos para instruções agressivas que incentivavam o agente a investigar todos os padrões suspeitos e errar ao sinalizar possíveis problemas.
Além disso, a arquitetura agente abriu uma superfície mais rica para experimentação. Conseguimos transferir mais informações do contexto estático para o contexto dinâmico, variando a quantidade de contexto inicial que o modelo recebeu e observando como ele se adaptou. O modelo extraiu consistentemente o contexto adicional necessário em tempo de execução, sem exigir que tudo fosse fornecido antecipadamente.
A mesma configuração nos permite iterar diretamente no próprio conjunto de ferramentas. Como o comportamento do modelo é moldado pelas ferramentas que ele pode chamar, mesmo pequenas mudanças no design ou na disponibilidade das ferramentas tiveram um impacto descomunal nos resultados. Por meio de várias rodadas de iteração, ajustamos e refinamos essa interface até que o comportamento do modelo estivesse consistentemente alinhado com nossas expectativas.
O que vem a seguir
Hoje, o Bugbot analisa mais de dois milhões de PRs por mês para clientes como Rippling, Discord, Samsara, Airtable e Sierra AI. Também executamos o Bugbot em todo o código interno do Cursor.
Olhando para o futuro, esperamos que cheguem regularmente novos modelos com diferentes pontos fortes e fracos, tanto de outros fornecedores como dos nossos próprios esforços de formação. O progresso contínuo requer encontrar a combinação certa de modelos, design de chicotes e estrutura de revisão. O Bugbot hoje é muito melhor do que o Bugbot no lançamento. Em alguns meses esperamos que melhore significativamente novamente.
Já estamos construindo esse futuro. Acabamos de lançar o Bugbot Autofix em Beta, que gera automaticamente um Agente de Nuvem para corrigir bugs encontrados durante análises de relações públicas. Os próximos recursos principais incluem permitir que o Bugbot execute código para verificar seus próprios relatórios de bugs e permitir pesquisas profundas quando encontrar problemas complexos. Também estamos experimentando uma versão sempre ativa que verifica continuamente sua base de código, em vez de esperar por solicitações pull.
Fizemos grandes avanços até agora que não seriam possíveis sem as contribuições de alguns companheiros importantes, incluindo Lee Danilek, Vincent Marti, Rohan Varma, Yuri Volkov, Jack Pertschuk, Michiel De Jong, Federico Cassano, Ravi Rahman e Josh Ma. Juntos, nosso objetivo continua sendo ajudar suas equipes a manter a qualidade do código à medida que seus fluxos de trabalho de desenvolvimento de IA aumentam.
Leia a documentação ou experimente o Bugbot hoje.
Fonte: theverge





