
Conforme discutido no Mozilla Connecto Firefox 130 apresentará um novo recurso experimental para gerar automaticamente texto alternativo para imagens usando um modelo de IA totalmente privado no dispositivo. O recurso estará disponível como parte do editor de PDF integrado do Firefox, e nosso objetivo final é disponibilizá-lo na navegação geral para usuários com leitores de tela.
Por que texto alternativo?
As páginas web têm uma estrutura fundamentalmente simples, com semântica que permite ao navegador interpretar o mesmo conteúdo de forma diferente para pessoas diferentes com base nas suas próprias necessidades e preferências. Isto é uma grande parte do que achamos que torna a Web especial e o que permite ao navegador atuar como um agente do usuário, responsável por fazer a Web funcionar para as pessoas.
Isto é particularmente útil para tecnologias assistivas, como leitores de tela, que são capazes de trabalhar junto com recursos do navegador para reduzir obstáculos para as pessoas acessarem e trocarem informações. Para páginas da web estáticas, isso geralmente pode ser conseguido com muito pouca interação do site, e esse acesso tem sido enormemente benéfico para muitas pessoas.
Mas mesmo para uma página estática simples, existem certos tipos de informações, como texto alternativo para imagens, que devem ser fornecidas pelo autor para fornecer uma experiência compreensível para pessoas que usam tecnologia assistiva (conforme exigido pelas especificações). Infelizmente, muitos autores não fazem isso: o Web Almanac relatou em 2022 que quase metade das imagens não tinha texto alternativo.
Até recentemente, não era viável para o navegador inferir texto alternativo de qualidade razoavelmente alta para imagens, sem enviar dados potencialmente confidenciais a um servidor remoto. No entanto, os desenvolvimentos mais recentes em IA permitiram que este tipo de análise de imagem acontecesse de forma eficiente, mesmo numa CPU.
Estamos adicionando um recurso ao editor de PDF do Firefox Nightly para validar essa abordagem. À medida que o desenvolvemos e aprendemos com a implantação, nosso objetivo é oferecê-lo aos usuários que gostariam de usá-lo durante a navegação para ajudá-los a entender melhor as imagens que, de outra forma, seriam inacessíveis.
Gerando texto alternativo com pequenos modelos de código aberto
Estamos usando modelos de aprendizado de máquina baseados em Transformer para descrever imagens. Esses modelos estão cada vez melhores na descrição do conteúdo da imagem, mas são compactos o suficiente para operar em dispositivos com recursos limitados. Embora não possam superar um modelo de linguagem grande como GPT-4 Turbo com Vision ou LLaVA, eles são suficientemente precisos para fornecer informações valiosas no dispositivo em uma diversidade de hardware.
Arquiteturas de modelo como BLIP ou mesmo VIT que foram treinadas em conjuntos de dados como COCO (Common Object In Context) ou Flickr30k são boas para identificar objetos em uma imagem. Quando combinados com um decodificador de texto como o GPT-2 da OpenAI, eles podem produzir texto alternativo com 200 milhões ou menos de parâmetros. Uma vez quantizados, esses modelos podem ter menos de 200 MB em disco e serem executados em alguns segundos em um laptop – uma grande redução em comparação com os gigabytes e recursos que um LLM requer.
Exemplo de saída
A imagem abaixo (retirada do conjunto de dados COCO) é descrita por:
- FOGO – nosso modelo de parâmetros de 182M usando uma versão destilada do GPT-2 junto com um codificador de imagem Vision Transformer (ViT).
- MODELO DE BASE – um modelo ViT+GPT-2 um pouco maior
- TEXTO HUMANO – a descrição fornecida pelo anotador do conjunto de dados.
Ambos os modelos pequenos perdem precisão em comparação com a descrição fornecida por uma pessoa, e o modelo básico é confundido pela posição das mãos. O modelo Firefox está um pouco melhor nesse caso e captura o que é importante.
O que importa pode ser sugestivo em qualquer caso. Observe como a pessoa não escreveu sobre o ambiente do escritório ou sobre as cerejas do bolo, e especificou que as velas eram longas.
Se executarmos a mesma imagem em um modelo como o GPT-4o, os resultados serão extremamente detalhados:
A imagem retrata um grupo de pessoas reunidas em torno de um bolo com velas acesas. O destaque está no bolo, que tem cobertura de geleia vermelha e algumas cerejas. Existem várias velas acesas em primeiro plano. Ao fundo, há uma mulher sorrindo, vestindo um suéter cinza de gola alta, e algumas outras pessoas podem ser vistas, provavelmente em um escritório ou ambiente interno. A imagem transmite uma atmosfera comemorativa, possivelmente um aniversário ou uma ocasião especial.
Mas esse nível de detalhe no texto alternativo é impressionante e não prioriza as informações mais importantes. A brevidade não é o único objetivo, mas é um ponto de partida útil, e a precisão concisa em um primeiro rascunho permite que os criadores de conteúdo concentrem suas edições na falta de contexto e detalhes.
Portanto, se pedirmos ao LLM uma descrição de uma frase, obteremos:
Um grupo de pessoas em um escritório comemora com um bolo de aniversário iluminado em primeiro plano e uma mulher sorridente ao fundo.
Possui mais detalhes do que nosso modelo pequeno, mas não pode ser executado localmente sem enviar sua imagem a um servidor.
Pequeno é lindo
Executar inferência localmente com modelos pequenos oferece muitas vantagens:
- Privacidade: Todas as operações estão contidas no dispositivo, garantindo a privacidade dos dados. Não teremos acesso às suas imagens, conteúdo em PDF, legendas geradas ou legendas finais. Seus dados não serão usados para treinar o modelo.
- Eficiência de Recursos: Modelos pequenos eliminam a necessidade de GPUs de alta potência na nuvem, reduzindo o consumo de recursos e tornando-os mais ecológicos.
- Maior transparência: O gerenciamento interno de modelos permite a supervisão direta dos conjuntos de dados de treinamento, oferecendo mais transparência em comparação com alguns grandes modelos de linguagem (LLMs).
- Monitoramento da Pegada de Carbono: Modelos de treinamento internos facilitam o rastreamento preciso das emissões de CO2 usando ferramentas como o CodeCarbon.
- Facilidade de melhoria: como o retreinamento pode ser concluído em menos de um dia em uma única peça de hardware, ele permite atualizações e aprimoramentos frequentes do modelo.
Integrando Inferência Local no Firefox
Estendendo a arquitetura de inferência de traduções
O Firefox Translations usa o projeto Bergamot desenvolvido com o tempo de execução de inferência Marian C++. O tempo de execução é compilado no WASM e há um arquivo de modelo para cada tarefa de tradução.
Por exemplo, se você executar o Firefox em francês e visitar uma página em inglês, o Firefox perguntará se você deseja traduzi-la para o francês e baixará o modelo inglês para francês (~20MiB) junto com o tempo de execução de inferência. Este é um download único: as traduções acontecerão completamente offline assim que os arquivos estiverem no disco.
O tempo de execução e os modelos WASM são armazenados no serviço Firefox Remote Settings, o que nos permite distribuí-los em escala e gerenciar versões.
A tarefa de inferência é executada em um processo separado, o que evita que o navegador ou uma de suas guias trave se o tempo de execução de inferência falhar.
ONNX e Transformers.js
Decidimos incorporar o tempo de execução ONNX no Firefox Nightly junto com a biblioteca Transformers.js para estender a arquitetura de tradução para realizar diferentes trabalhos de inferência.
Assim como o Bergamot, o tempo de execução ONNX possui uma distribuição WASM e pode ser executado diretamente no navegador. O projeto ONNX introduziu recentemente suporte WebGPU, que eventualmente será ativado no Firefox Nightly para este recurso.
Transformers.js fornece uma camada Javascript sobre o tempo de execução de inferência ONNX, facilitando a adição de inferência para uma enorme lista de arquiteturas de modelo. A API imita a muito popular biblioteca Python. Ele faz todo o trabalho tedioso de preparar os dados que são passados para o tempo de execução e converter a saída de volta em um resultado utilizável. Ele também trata do download de modelos do Hugging Face e do armazenamento em cache deles.
Na documentação do projeto, é assim que você pode executar um modelo de análise de sentimento em um texto:
import { pipeline } from '@xenova/transformers';
// Allocate a pipeline for sentiment-analysis
let pipe = await pipeline('sentiment-analysis');
let out = await pipe('I love transformers!');
// [{'label': 'POSITIVE', 'score': 0.999817686}]Usar Transformers.js nos dá confiança ao testar um novo modelo com ONNX. Se sua arquitetura estiver listada na documentação do Transformers.js, é uma boa indicação de que funcionará para nós.
Para vendê-lo no Firefox Nightly, alteramos ligeiramente seu lançamento para distribuir o ONNX separadamente do Transformers.js, eliminamos peças relacionadas ao Node.js e corrigimos aquelas irritantes chamadas eval() que acompanham a biblioteca ONNX. Você pode encontrar aqui o script de construção que foi usado para preencher o diretório do fornecedor.
A partir daí, reutilizamos a arquitetura de tradução para executar o tempo de execução ONNX dentro de seu próprio processo e executar Transformers.js com um sistema de cache de modelo personalizado.
Cache de modelo
O projeto Transformers.js pode usar modelos locais e remotos e possui um mecanismo de cache usando o cache do navegador. Como estamos executando inferência em um web trabalhador isolado, não queremos fornecer acesso ao sistema de arquivos ou armazenar modelos dentro do cache do navegador. Também não queremos usar o Hugging Face como hub de modelo no Firefox e queremos servir arquivos de modelo de nossos próprios servidores.
Como Transformers.js fornece um retorno de chamada para um cache personalizado, implementamos uma camada de cache de modelo específica que baixa arquivos de nossos próprios servidores e os armazena em cache no IndexedDB.
À medida que o projeto cresce, prevemos que o navegador armazenará mais modelos, que podem ocupar um espaço significativo em disco. Planejamos adicionar uma interface no Firefox para gerenciar modelos baixados para que nossos usuários possam listá-los e remover alguns, se necessário.
Ajustando um modelo ViT + GPT-2
Ankur Kumar lançou um modelo popular no Hugging Face para gerar texto alternativo para imagens e blogou sobre isso. Este modelo também foi publicado como pesos ONNX por Joshua Lochner para que pudesse ser usado em Transformers.js, consulte https://huggingface.co/Xenova/vit-gpt2-image-captioning
O modelo está fazendo um bom trabalho – mesmo que em alguns casos tenhamos tido melhores resultados com https://huggingface.co/microsoft/git-base-coco – mas a arquitetura GIT ainda não é suportada em conversores ONNX, e com menos de 200 milhões de parâmetros, a maior parte da precisão é obtida concentrando-se em bons dados de treinamento. Então escolhemos o ViT para nosso primeiro modelo.
Ankur usou o codificador de imagem google/vit-base-patch16-224-in21k e o decodificador de texto GPT-2 e os ajustou usando o conjunto de dados COCO, que é um conjunto de dados de mais de 120 mil imagens rotuladas.
Para reduzir o tamanho do modelo e agilizá-lo um pouco, decidimos substituir o GPT-2 pelo DistilGPT-2 — que é 2 vezes mais rápido e 33% menor de acordo com sua documentação.
Usar esse modelo em Transformers.js deu bons resultados (veja o código de treinamento no GitHub – mozilla/distilvit: modelo de imagem para texto para PDF.js).
Melhoramos ainda mais o modelo para nosso caso de uso com um conjunto de dados de treinamento atualizado e algum aprendizado supervisionado para simplificar a saída e mitigar alguns dos preconceitos comuns em modelos de imagem para texto.
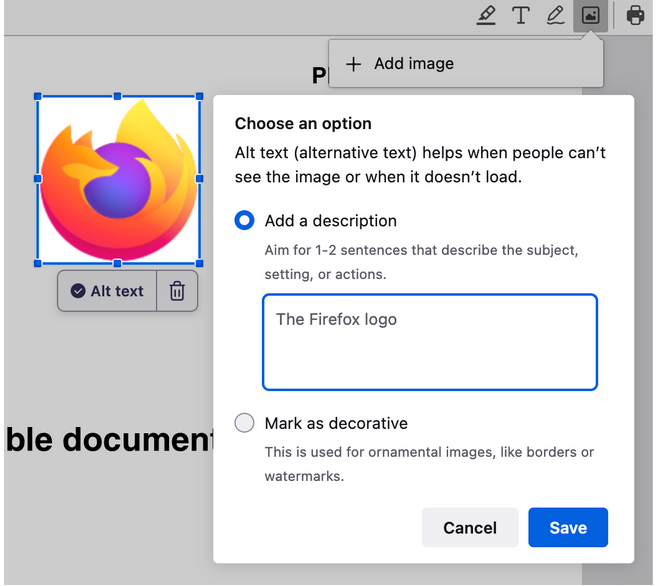
Geração de texto alternativo em PDF.js
O Firefox é capaz de adicionar uma imagem em um PDF usando nossa popular biblioteca pdf.js de código aberto:
A partir do Firefox 130, geraremos automaticamente um texto alternativo e deixaremos o usuário validá-lo. Assim, cada vez que uma imagem é adicionada, obtemos um array de pixels que passamos para o mecanismo de ML e alguns segundos depois, obtemos uma string correspondente a uma descrição desta imagem (veja o código).
Na primeira vez que o usuário adicionar uma imagem, terá que esperar um pouco para baixar o modelo (o que pode levar alguns minutos dependendo da sua conexão), mas os usos subsequentes serão muito mais rápidos, pois o modelo será armazenado localmente.
No futuro, queremos ser capazes de fornecer um texto alternativo para qualquer imagem existente em PDFs, exceto imagens que contenham apenas texto (normalmente é o caso de PDFs contendo livros digitalizados).
Próximas etapas
Nosso gerador de texto alternativo está longe de ser perfeito, mas queremos adotar uma abordagem iterativa e melhorá-lo abertamente. O mecanismo de inferência já chegou ao Firefox Nightly como um novo componente ml junto com uma página de documentação inicial.
No momento, estamos trabalhando para melhorar os conjuntos de dados e modelos de imagem para texto com o que descrevemos nesta postagem do blog, que será continuamente atualizada em nossa página Hugging Face.
O código que produz o modelo está no Github https://github.com/mozilla/distilvit e o aplicativo da web que estamos construindo para nossa equipe melhorar o modelo está localizado em https://github.com/mozilla/checkvite. Queremos ter certeza de que os modelos e conjuntos de dados que construímos, e todo o código usado, sejam disponibilizados para a comunidade.
Assim que o recurso de texto alternativo no PDF.js amadurecer e provar que funciona bem, esperamos disponibilizar o recurso na navegação geral para usuários com leitores de tela.
Engenheiro sênior de aprendizado de máquina trabalhando em Firefox e especialista em Python.
Mais artigos de Tarek Ziadé…





